캐글 코리아 캐글 스터디 필사 1주차
깨작깨작 시작한지는 좀 됐는데 본격적으로 시작합니다.
24.12.16 시작
https://kaggle-kr.tistory.com/32
[이유한님] 캐글 코리아 캐글 스터디 커널 커리큘럼
유한님이 이전에 공유해주신 캐글 커널 커리큘럼 정리본입니다. 다들 Keep Going 합시다!! 커리큘럼 참여 방법 필사적으로 필사하세요 커널의 A 부터 Z 까지 다 똑같이 따라 적기! 똑같이 3번적고 다
kaggle-kr.tistory.com
해당 글을 참고하였습니다!

- matplotlib.pyplot 모듈 : 데이터를 시각화해주는 라이브러리( ≒ MATLAB)
- plt.style.use : 그래프 스타일 설정
- missingno : 결측치/결측값 시각화 -> 데이터 분석하는데 있어서 잘못된 분석 결과 or 에러 발생
* 결측치 : 수집된 데이터 셋 중에 관측되지 않는 값 (=Na / =Null)
- %matplotlib inline : 코드를 실행한 브라우저에서 바로 볼 수 있게 함
1. Dataset 확인

여기서 좀 시간이 걸렸는데, FILE -> Add input -> titanic 검색 -> Titanic - Machine Learning from Disaster의 +모양 클릭한 후 Add input 창을 닫아주면

input에 데이터셋이 저장된 것을 확인할 수 있다. 여기서 test.csv와 train.csv의 위치를 복사해서 코드에 입력하면 된다.
pd.read_csv : .csv 파일을 불러와서 pandas 패키지에서 제공하는 Pandas DataFrame 형식으로 만들어주는 함수
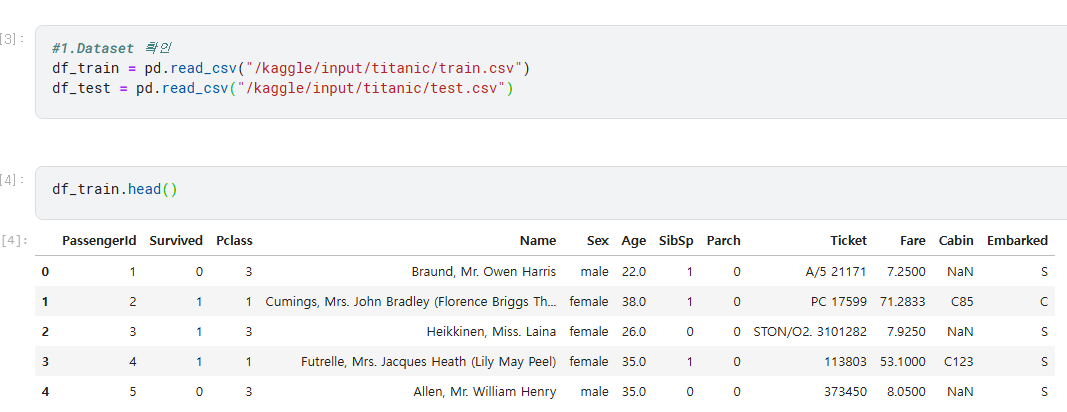
df_train.head()는 데이터셋의 첫 5행을 출력 (함수의 default 값이 5)
만약 15행을 출력하고 싶다? -> df_train.head(15)

(train - 모델 훈련 / test - 모델 검증)
- describe() : 통계 정보 요약
1-1. Null data check


Titanic 데이터셋에서 결측치(null 값)의 비율을 계산 -> 결측치를 처리해야 함(전처리)
- df_train.columns: 데이터프레임의 모든 열을 순회
- df_train[col].isnull().sum() : 현재 열 Null 값 개수 계산
- df_train[col].shape[0] : 총 데이터 개수
위의 결과를 보면 train와 test의 데이터셋에서 Age, Cabin의 결측치를 확인할 수 있음. 이를 전처리해야 함.
Fare(요금)과 Embarked(승선)에도 약간의 결측치가 나오는데 이도 함께 살펴봐야 함.
따라서 나이와 선실 위치가 생존율에 크게 영향을 끼쳤다는 것을 알 수 있음.

- msno.matrix : 매트릭스 형태로 시각 / 흰색 - 결측치
- msno.bar : 막대그래프 형태로 시각화
- iloc(integer location) : 정수 인덱스 사용 -> 데이터 프레임 행/열 순서 나타냄



참고했던 블로그 글의 sns.countplot('Survived', data=df_train, ax=ax[1]) 코드를 실행해보면 아래 사진과 같이 오류가 뜨는 것을 확인할 수 있다.

이는 x나 y를 명시하지 않고 data만 지정하게 되면 countplot() 함수가 자동적으로 data의 전체 데이터를 대상으로 시각화를 하려고 하기 때문이다. data와 다른 값의 충돌이 발생하여 오류가 생기는 것이다.
그러므로, x축을 명시해주면 문제 해결!
2-1. Pclass

'Pclass'와 'Survived'를 'Pclass로 묶어서 이를 평균내면 각 pclass 별 생존율이 나옴.
- groupby 함수 : 같은 값을 가진 행끼리 그룹


표에 나온 숫자를 보면 'Pclass 3'의 생존자 수가 'Pclass2'보다 많다라고 볼 수 있는데,
이를 생존율로 나타내야 한다.
- Pclass 1 : 136/80+136 = 약 63%
- Pclass 2 : 87/97+87 = 약 47%
- Pclass 3 : 119/372+119 = 약 24%
Pclass3의 생존율이 가장 낮은 것을 볼 수 있음!
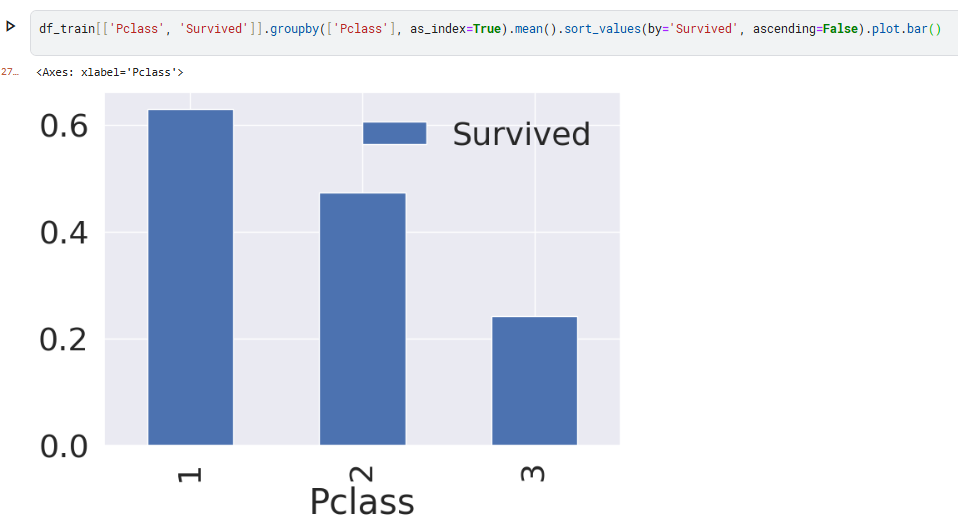
- mean() : 평균값 = 생존율 / Pclass1의 평균값 0.63 -> 63% 생존
- sort.values(by='Survived', ascending=False) : Survived 열의 값을 내림차순으로 정렬
(ascending=True -> 오름차순)

- y_position : 타이틀의 위치 (그래프에서 얼마나 떨어져있는가)
- ax=ax[0] : 첫번째 그래프(서브플롯) / ax=ax[1] : 두번째 그래프
-> 클래스가 높을수록, 생존율이 높다.
2-2. Sex(성별)

-> 여자의 생존율이 더 높다
이를 표로 나타내보자.

- female : 233/81+233= 약 74%
- male : 109/468+109= 약 19%
-> 남자보다 여자의 생존율이 더 높음
2-3. Both Sex and Pclass

블로그에서는 sns.factorplot으로 되어있는데 찾아보니 seaborn 0.9.0 버전부터 없어졌다고 함.
이를 대체하기 위해 sns.catplot 사용!
(kind='point' : 포인트 플룻 / kind='bar' : 막대그래프 / kind='box' : 박스 플롯 / kind='violin' : 바이올린 플룻)
- estimator = 'mean' : 평균 생존율에 . 찍음 (한국어로 추정량)

2-4. Age



- *KDE(Kernel Density Estimation) : 커널밀도추정 그래프
*추가 학습 필요 - 추후에 공부한 부분 포스팅
- 1st Class로 갈수록 나이 높은 사람이 많아짐.

2-5. Pclass, Sex, Age

그래프에서 알 수 있는 것 :
1. 클래스가 높을수록 생존율이 더 높다.
2. 나이가 어릴수록 생존율이 높다.
3. 남성보다 여성의 생존율이 더 높다.
2-6. Embarked (탑승 항구)


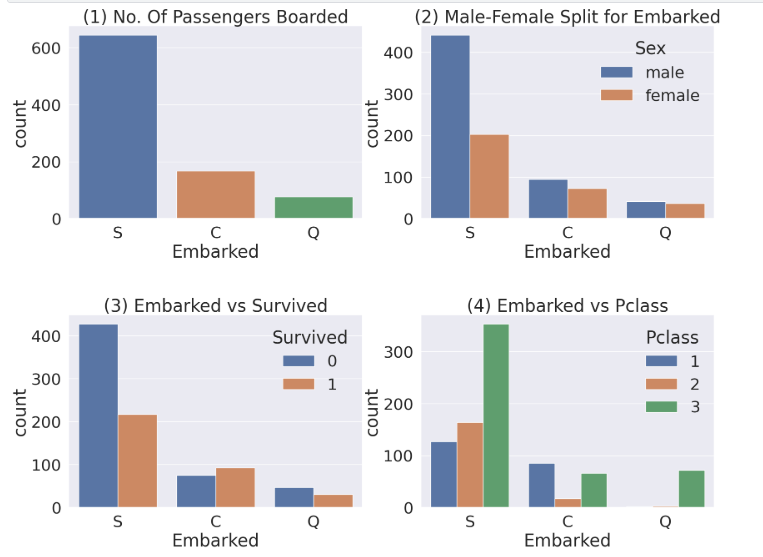
- 범주별 데이터 분포 비교하고, 세부 분포 확인!
1. S 탑승구의 탑승자가 가장 많음
2. S 탑승구에서의 남자 탑승자가 더 많고, C와 Q는 비슷
3. S의 남자 탑승자가 많기 때문에 사망자도 많음
4. S 탑승구에 3rd class가 많아서 사망율도 높음
2-7. Family - SibSp(형제 자매) + Parch(부모, 자녀)


1. 탑승객 1인이 가장 많고, 2인, 3인 순서대로 많다.
2. 1명일 때와 5명 이상일 때 생존율이 낮고, 2,3,4명일 때는 생존율이 높은 모습을 볼 수 있다. 4명일 때의 생존율이 가장 높다.
2-8. Fare(탑승요금)

- distplot : 데이터의 히스토그램을 그려주는 함
Skewness(왜도): 데이터 분포의 좌우 비대칭도



튜토리얼 끝-!